
A “diverse group of people forming a choir, captured in a natural, unposed moment” according to leonardo.ai.
How can I know if the person on the other side of the phone is indeed that person? How can we be sure that a political representative has really said what we just heard? How can you connect with any voice if they all become alleged voices, mediated, undependable sound streams in a public arena in which synthesis has become a commodity?
This research project dwells on the ways voice cloning technology upends historically-given distinctions between physical and metaphysical aspects of voice, and how it questions long-standing ideas about presence in vocal phenomena. The study explores vocal clones as “presentational” and reflect on their possible implications for Western understandings of voice, identity, and the nature of vocal experience. The aim is to examine not only the technology itself, but how it is gradually shaping our perceptions of representation.
Voice cloning as a presentational recording
Voice Cloning Technology (VcT) introduces a new dimension to vocal reproduction, in transcending and reinventing voice recording. The “clone” is molded on a certain vocality’s characteristics: in this sense, it is intimate with traditional audio capture. On the other hand, however, the two differ substantially.
The cloned voice presents a voice in effigy, as a simulacrum or formal replica, which transforms the source material rather than immobilizing it. Instead of speaking of a certain vocal experience—a voice which did a certain thing—the “clone” presents that voice while it is doing things that the source (or target) has never done.
Nonetheless, such “Deepfakes” do not disrupt the mechanism of representation; quite the opposite. Borrowing from Suzanne Langer’s terminology, we can therefore understand the vocal clone as a “presentational recording”: a replica that re-creates a vocal experience in a virtual, quasi-vocal space.
The vocal clone presents a voice without simply referring to it, but by mirroring its form in a malleable dimension. This new elastic and reusable dimension is increasingly disrupting many aspects of our relationship to voice: our sense of vocality as a mark of truth, see for example voice ID systems which are under threat (Cox 2023); our sense of identity as a site of uniqueness (Cavarero 2003), whereas clones make voices reproducible and shareable; and not least our sense of representation, since the possibility of a voice being synthetic—even when it feels altogether organic—affects the way one listens to any voice (Scola 2023).
As in practice so in theory, hyperrealistic synthesis is disrupting our sense of representation in unprecedented ways. To begin with, it is eroding people’s trust, after three years of increasingly efficient and common scams, frauds, and deepfakes.

Unsettling details from a choir photo via leonardo.ai.
Definitions and working assumptions
-
Vocal clones are replicas of a human voice, created using machine learning, natural language processing, and deep learning techniques. VcT encompasses various models used to generate natural-sounding, expressive speech (2) and singing (3). Unlike standard voice synthesis that used generic, pre-trained voices, VcT mimics specific vocalities on demand, hence the term “clone” (Tan et al. 2021; Hutiri, Papakyriakopoulos and Xiang 2024; Arık et al. 2018).
-
Speech synthesis produces speech utterances. They require at least one input: written text or speech (audio). Text-to-Speech (TTS) systems are the dominant approach and use text as the input. Speech-to-Speech (S2S) and voice conversion systems use speech as the input, and can transfer attributes from one utterance (e.g. identity, emotion, accent) to another (Ning et al. 2019; Prenger et al. 2019; Gritsenko et al. 2020; Wu et al. 2023; Lux, Koch, and Vu 2022; Wang et al. 2023; Betker 2023). TTS and S2S can be coupled with Speech-to-Text (S2T) systems (speech recognition) to allow human-machine vocal interaction.
-
Singing Voice Synthesis (SVS) is a frontier area of VcT that enables the generation of realistic singing voices. It also enables voice conversion (transforming the voice of a sung performance into that of another). While TTS is much more established, research into SVS for solo and choir singing applications is flourishing (Chen et al. 2024; Eliav et al. 2024; Kim et al. 2024; Li et al. 2024; Tang et al. 2024; Wang et al. 2024; Blaauw et al. 2019; Wu et al. 2024; Blaauw and Bonada 2017; Umbert et al. 2015; Hua 2018; Shirota et al. 2014).
-
Voice cloning ethics reflects the social context of vocal clones. It can be understood as a subgroup of “AI ethics”, which encompasses the principles aimed at ensuring ethical systems, as defined by different documents from academia, industry, non-profits and regulatory bodies, as well as civil society (for a survey, see Gornet and Viard 2023). These vary widely in content and highlighting both consensus and dissent among stakeholders. Recurring themes include transparency, justice, fairness, non-maleficence, responsibility, privacy, accountability, safety, well-being, human oversight, solidarity, explainability, and collaboration.
A brief history of hyperrealistic synthesis
Speech synthesis
VcT has rapidly advanced through the development of speech synthesis systems, leveraging deep learning techniques to replicate a target voice’s unique characteristics and style (Tan et al. 2021).
“Deep learning” refers to a method in which computers learn from experience, understanding the world through hierarchical concepts that build complex ideas from simpler ones. It is “deep” because “a graph of these hierarchies would be many layers deep” (Goodfellow, Bengio, and Courville 2016). In less than a decade, thanks to this method, VcT has achieved remarkable accuracy in capturing nuances such as tone, emotion, and accents, by systematically overcoming the limitations of one model in the next.
Initially, speech synthesis relied on analyzing and synthesizing acoustic features using a two-module system: a front-end for linguistic feature extraction via an acoustic model, and a back-end for audio waveform generation, vocalizing characters or phonemes with a vocoder (Ning et al. 2019). As the field evolved, synthesis systems incorporated end-to-end architectures, by improving the information loss that is inherent in traditional methods and reducing their reliance on vast datasets (Prenger et al. 2019). End-to-end architectures combine the acoustic model and the vocoder to generate waveforms directly from written text (Casanova et al. 2021).
A milestone was the introduction of Baidu’s Deep Voice in 2017. This model used neural networks at each synthesis stage, but suffered from error accumulation (Arık et al. 2018). Around the same time, Sotelo et al.’s Char2Wav and Google’s Tacotron integrated advanced neural networks, such as bidirectional RNNs and attention mechanisms (Sotelo et al. 2017; Wang et al. 2017).
Google further refined this approach with Tacotron 2, which combined LSTM networks and convolutional layers to improve voice cloning accuracy (Shen et al. 2018). More recent techniques also used convolutional and LSTM networks to accurately adjust speech rhythm (Blaauw et al. 2019).
Advances continued with Deep Voice 3 (Gritsenko et al. 2020) and Google’s 2019 model (Zhao et al. 2018), which introduced speaker-adaptive techniques and extracted speaker embeddings to clone voices from few voice samples. “Embeddings” are compact numerical representations of the characteristics of a speaker’s voice, captured in a vector form, and designed to distill the unique attributes of that voice into a low-dimensional space.

A documentary-style choir scene according to DALL-E.
Despite such advances, issues about naturalness and accuracy persisted, leading to further enhancements such as Microsoft’s FastSpeech 2 (Ren et al. 2021), which excelled in synthesis speed and sound quality but still struggled with the extraction of distinct voice traits (Wu et al. 2023).
The field saw significant innovations by 2022, marking VcT’s evolution from experimental to mainstream use. The TorToiSe system, introduced in April, utilized neural networks trained on extensive audio data to enable voice cloning from as few as two to four samples (Betker 2023).
Traditional TTS models have previously been limited by the size of datasets and the complexity of architectures themselves. TorToiSe leveraged the benefits of MEL spectrograms to produce high-quality audio waveforms faster and with lower energy consumption. This breakthrough was soon followed in October, with the introduction of a model developed by the Institute for Natural Language Processing at the University of Stuttgart, which merged multilingual TTS with zero-shot cloning, allowing quick adaptation to new languages and multiple speakers with minimal data (Lux, Koch, and Vu 2022).
In January 2023, new breakthroughs were achieved with the introduction of VALL-E, by Microsoft, which was able to generate high-quality speech from just a three-second sample, while maintaining high authenticity (Wang et al. 2023). Shortly after, in February, the ZSE-VITS model was introduced, which used a speaker encoder from TitaNet within a variational autoencoder framework. This model significantly enhanced timbre and prosody control (Li and Zhang 2023). By 2024, VcT achieved unprecedented levels of fidelity, effectiveness, and accessibility.

Another choir scene via leonardo.ai.
Singing voice synthesis
Singing voice synthesis (SVS), which builds upon speech synthesis, has its own unique history. Although it existed since the late 1950s (Cook 1996), up until the 2020s “producing singing voices indistinguishable from that of human singers has always remained an unfulfilled pursuit” (Cho et al. 2021: 1).
Before the adoption of neural networks, SVS relied on unit concatenation (Bonada and Serra 2007) in tandem with hidden Markov models, or HMM (Saino et al. 2006). Unit concatenation synthesizers, like Vocaloid, created the singing voice by selecting and stringing together voice elements from a database (Kenmochi and Ohshita 2007). This approach separately models the spectral envelopes, excitation, and duration of the singing voice, using speech parameter generation algorithms to create parameter trajectories (Tokuda et al. 2000). Despite the success of this approach, the naturalness achieved by neural networks has surpassed that of HMM-based SVS.
In recent years, various architectures have been used, including generic deep neural networks (Nishimura et al. 2016), convolutional neural networks (Nakamura et al. 2019), LSTM networks (Kim et al. 2018), and generative adversarial networks (Hono et al. 2019).
These advancements, along with the adoption of autoregressive sequence-to-sequence models (Lee et al. 2019), have significantly improved SVS systems and the musical quality of the generated sung performance. The latest architectures include Transformer-based systems, such as XiaoicSing (Lu et al. 2020) or HifiSinger, and diffusion denoising probabilistic models like DiffSinger (Cho et al. 2021). However, these models typically require vast training datasets, which can be scarce (Zhuang et al. 2021).
Recent developments focused on overcoming such challenges. Enhancing the synthesis fidelity, efficiency, and adaptability is the major focus (Wang, Zeng and He 2022), while the reliance on extensive singing data remains one of the biggest challenges (Kakoulidis et al 2024).
Other issues include the inability to control style attributes such as gender and vocal range (Wang et al. 2024); code-switch across multiple languages (Zhou et al. 2023); and the difficulty of synthesizing singing in so-called Out-of-Domain scenarios, where target vocal attributes are not available during machine training (Zhang et al. 2024).
New solutions and systems are being developed and released as I write. A quick search on arXiv reveals that eleven papers on SVS were announced in June 2024 alone. Exploring these in detail would be of limited utility, also given the rapid pace at which the field evolves, and would exceed the scope of this paper, which focuses not on the technology itself but on its applications.
To name only a few interesting solutions, the GOLF model (GlOttal-flow LPC Filter), integrates physical modeling of the human voice, using a glottal model and IIR filters to simulate the vocal tract and the physical properties of sound generation (Yu and Fazekas 2023).
StyleSinger introduces techniques such as a Residual Style Adaptor and Uncertainty Modeling to enhance the model’s ability to generalize to styles that are not represented in the training data (Zhang et al. 2024).
Addressing the task of cross-lingual synthesis, BiSinger develops a shared representation for English and Chinese (Zhou et al. 2023), whereas CrossSinger utilizes the International Phonetic Alphabet to unify language representations (Wang, Zeng, Chen, and Wang 2023).
Other innovative and musically convincing models include: Make-A-Voice, which utilizes a coarse-to-fine approach for scalable voice synthesis from discrete representations (Huang et al. 2023); NANSY, which operates in a self-supervised manner, modeling only essential features (Choi, Yang, Lee and Kim 2022); XiaoiceSing2, which improves upon its predecessor by focusing on the details in mid- and high-frequency ranges (Wang, Zeng 2022); and Muskits, an open-source platform which facilitates a fair comparison among various available models (Shi et al. 2022).
As of late June 2024, the landscape of VcT is vast and evolves fast. Mainstream, established TTS tools include services such as Play.ht, ElevenLabs, Murf, Voice.Ai, Descript, Resemble, Lovo, Podcastle, Fliki, iMyFoneVoxBox, Speechelo, and Speechify, each offering various features.
Experimental SVS models include, in addition to those already mentioned and among others, Period Singer, VISinger2+, TokSing, MakeSinger, SingIt!, CONTUNER, Prompt-Singer, HiddenSinger, WeSinger2, SUSing, SingAug, and Karaoker-SSL, demonstrating the vibrancy of the field.
The hyperrealistic synthetic voices produced by these tools are used daily worldwide for a variety of purposes. All such tools, which are based on the deep learning techniques described earlier, yield extremely convincing results. As we will explore in the next section, it is this very hyperrealism that generates the greatest benefits and the greatest risks.
Benefits and challenges
The following figure presents a survey of benefits and challenges of VcT, informed by a synopsis of scholarly and popular media publications.
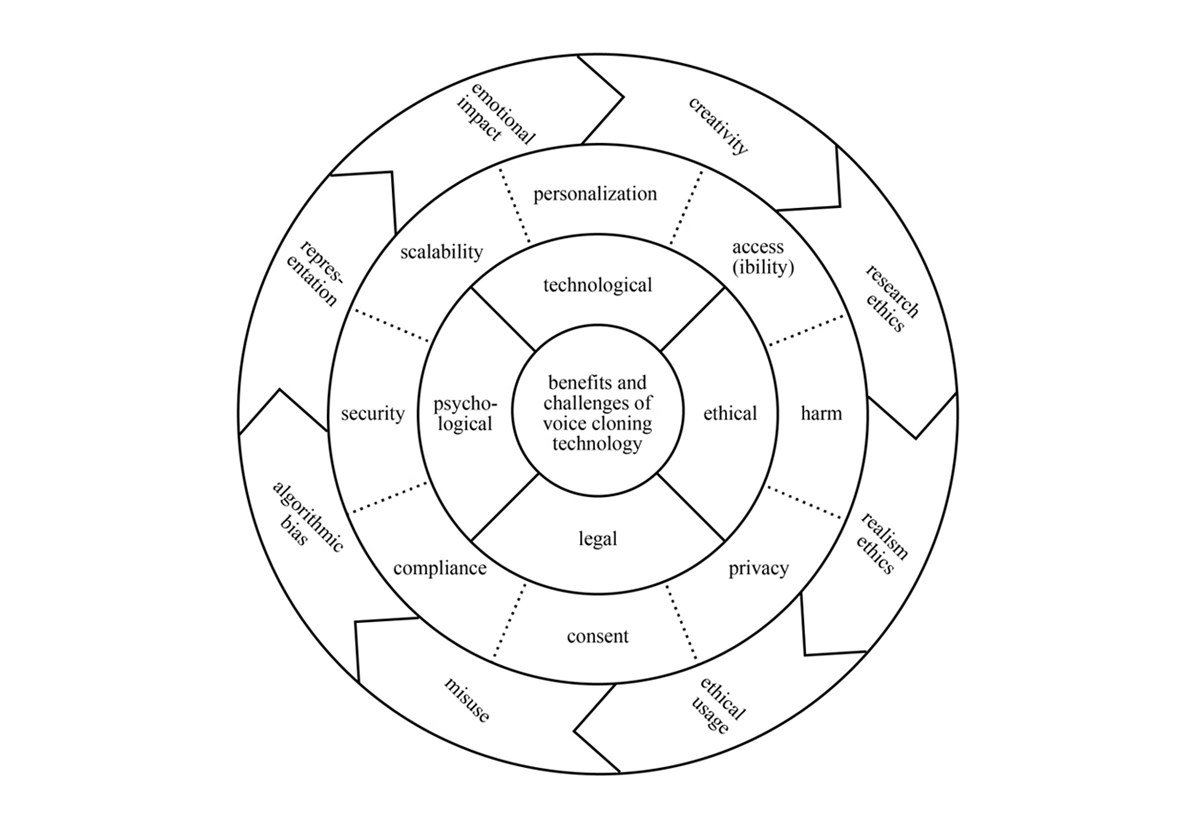
Benefits and challenges of voice cloning technology (from Venturi 2024, forthcoming).
The concentric circles illustrate a layered and interconnected classification. The inner circle highlights four superordinate aspects. Each is associated with specific types of issues and advantages, explored moving outward in the diagram. The middle circle lists more specific subordinate aspects, which often overlap. The outer circle introduces broader frameworks and ideally rotates in a clockwise direction, informing all instances in the middle circle. While most instances in the figure fulfill multiple aspects, this simplified representation helps to clarify their connections.
On the statute of voice cloning technology
The vocal clone does not provide a description of a vocal phenomenon, does not speak of it, as an audio recording does, but presents the vocal phenomenon in effigy, “like a simulacrum or a formal replica that evokes an echo of it” (Wright 2022: 354). Considering the vocal clone as an immobile reproduction is a mistake: It is not an immobilization of the voice, but rather its transformation, and this places cloning at an ontologically new level (one that was unthinkable only until few years ago). Indeed, the cloned voice does not express the source voice at the behavioral level, but represents it, records it in a virtual or quasi-vocal dimension.
Although the clone stems from a capture of the characteristics and habits of a certain vocality—that is, as Adriana Cavarero reminds us, of a unique person —the important thing is that the clone differs substantially from a simple audio recording because it does not reproduce the voice, it produces its reproductions, it re-presents it in autonomy. To indicate this distinction, we can borrow from Langer and call the clone a presentational recording. The term highlights the fact that the clone does not refer to a voice but presents it in effigy.
Nota bene: Hyperrealistic voice synthesis is the presentational recording, not its outputs. The voice data, the processors, the service, and the engineers are its corollaries. Then there’s the output, the final synthesized vocalization; yet the latter is altogether similar to any other recorded utterance. Such is the ontological breakthrough: the same recorded utterance could have been uttered by a person or by a machine. It could have been recorded or generated. Today, in the absence of a voicer in the flesh, it is increasingly harder to know for sure.
Therefore, the presentational recording is the clone, not the cloned. It is in this sense that the term “voice cloning” is best understood, beyond metaphorical language (the term “clone” is a metaphor, since we are not taking about another, identical voice but we are talking about a deep learning model and a vocoder). The vocal clone operates through the modalities by which it is constructed and trained by machine learning. That is, its actual form is a simulacrum of a vocal experience. It mirrors the vocal form and, yet, “not as a simple reflection in a glass, but in the sense of re-creating it in a new form” (Wright 2022: 354). The form of such vocal experience is forged in the flesh of the biopsychosocial life of the subject who lends their voice to cloning (willingly or not) at a given moment and in a given place. The vocal clone embodies therefore the re-presentation of that situated vocal experience and no other. We cannot conclude that the vocal clone is disembodied.

Another choir photo via DALL-E.
Sources and targets
The presentational recording of a voice, or the vocal clone, opens up the possibility of probing into what the source voice does, into what it was able to do, at the time and place of capturing the source material. We can probe so deeply into that form, once (if) we have access to the synthesis model and the voice data, that we are at liberty to bend the presentational recording to any representation. We can say or sing whatever we want with the clone. Crucially, the clone can be used to present things that the source voice has never presented. Things that the person who has lent their voice to cloning would never ever do. Clearly, no audio recording does that.
The voice clone is autonomous from the cloned voice. By securing autonomy, it brings the characteristics of the source voice elsewhere. Within the virtual, quasi-vocal space of hyperrealistic synthesis, located elsewhere, the source voice(r) becomes at once fully relevant and fully irrelevant. Who and what is this clone presenting? Such a question appears both central and foolish. Yes, it presents that very style, timbre, and tone. But does it reproduce it? No, it only presents it. Such an apparently theoretical shift has severe practical consequences.
We can use the clone of someone’s child to scam the parents and have them send money (Puig 2023); we can clone a politician’s voice and convince people not to vote (Kramer 2023); we can send an audio recording of my very voice while am in prison (Vincent 2023). These are but three real life examples from 2023 alone. The problem is as simple as nasty: the cloned voicer will be represented by what their cloned voice does. The underlying paradox, then, is as follows: if I have a cloned voice say something that the original voicer would have never said, this person will be simultaneously one hundred percent present and one hundred percent absent in that voice. Once my voice is cloned, it is no longer ‘mine’. Yet, it remains ‘my’ voice. Without any supporting subtitle or watermark stating that this is not me, it appears to be me vocalizing.
An interesting distinction, then, appears: the difference between a source voice and a target voice. In practice, these are the same thing (both terms are used interchangeably): From the perspective of the original material used to train the cloning model, it is a “source voice”; from the perspective of the extent to which we can faithfully replicate that material, it is a “target voice”. But in theory, this minuscule shift in perspective, this change in terminology, clarifies how each source voice can become a target.
We are no longer the source of representation; we become the target of this representation. The voice produces me in full; we no longer produce it, not even a single phoneme. How can we, then, nonchalantly send a voice message when it can be transformed into countless other messages we never sent, but which seem to all intents and purposes to have been sent by us? Who else could ever be speaking, in this new messages, if not us? Where are “we” speaking from, then?
Our voice, captured in an audio recording, swiftly transforms from being the source of that material into a presentational target. We realize, this way, that we no longer are at liberty to say that that voice is ours. Perhaps, it is more correct to say that we are theirs. If until half decade ago this but a was a theorem, an image, a phenomenological perspective, in 2024 this has become a legal issue. Something that voice studies have grasped in theory for some time now (at least from Steven Connor onward) dramatically becomes a pragmatic, day-by-day problem.
It doesn’t surprise, indeed, that the White House Deputy Chief of Staff has said, “voice cloning is one thing that keeps me up at night” (Reed, quoted in Scola 2023).
The form of the vocal clone is an inorganic creation that follows the contour of an empathic experience and thus has important effects: it provides embodied perception with a tangible, acousmatic, and disembodied reality; it creates a sonic snapshot whereby the characteristics of one vocality can be preserved and put back into action to do things that exceed the source of the cloning; finally, by making the voice a target, cloning technology consigns vocality to a dimension forever detached from physiology without however renouncing the bond of empathy, uniqueness, credibility—the bond of that which makes a voice a voice and not a robotic reproduction or a description recorded on whatever medium.

A documentary-style choir scene via DALL-E.
After voice cloning technology
The clone’s capacity to present a voice in effigy, while remaining fundamentally different from an audio recording, positions it as a unique form of transitional phenomenon in a hyper-mediated soundscape. At a close reading, contemporary voice synthesis calls for a reconsideration—not that it is the first—of the boundaries between presence and absence in the realm of vocal experience. For truly disembodied (and yet perfectly convincing) synthetic voices put truly embodied and organic voices in a new light.
Such reconsideration should begin with a crime: trying to think about voices as such, voices in themselves. This criminal perspective seems to obliterate decades of non-essentialist research and Western theoretical development on presence and voice. What we get in return, however, are tools to address and not understate the promises and threats of voice cloning to our perception, experience, and knowledge of the human voice. What we get is a warning: if voices never “are” but always “are done”, then what a voice does—what things we do with voices—is that which matters. Yet if our voices can be easily used to do things we did not or would never do, we are clearly not in possession of our own voices—for in many ways we never were, but never so bluntly and mundanely so. After voice cloning technology, the most speculative theories of voice are turned into a commodity.
Full list of references and sources.
Technical breviary
Deep Learning Techniques
For an overview of deep learning techniques, see Mathew, Amudha and Sivakumari 2021. For a thorough exploration of the matter, the standard textbook is Goodfellow, Bengio, and Courville 2016.
Approaches to Voice Cloning
The two main approaches are adaptation and encoding (Arık et al. 2018). Speaker adaptation fine-tunes a model for a new speaker using gradient descent, which iteratively adjusts parameters to decrease error. Speaker encoding uses an additional network to create new speaker profiles based on sound characteristics.
Recurrent Neural Networks (RNNs)
Neural networks designed for sequence prediction. They process data sequentially, maintaining a memory of previous inputs to influence the processing of future inputs.
Attention Mechanisms
Enable models to weigh the importance of different pieces of data differently. In neural networks dealing with sequences, attention mechanisms help the model focus on relevant parts of the input to make decisions.
Long Short-Term Memory (LSTM) Networks
An advanced type of RNN that can learn and remember over long sequences without the risk of vanishing or exploding gradients. Well-suited for tasks where audio input spans long durations, such as speech synthesis.
Convolutional Layers
Use convolution to process data. In neural networks, convolutional layers systematically apply learned filters to input data, extracting important features, such as edges in images or raw audio waveforms.
Mel Spectrogram
A visual representation that maps the loudness of an audio signal over time at various frequencies, adjusted to the Mel scale to reflect human auditory perception.
Zero-Shot Learning
A machine learning technique where the model performs tasks or makes predictions for scenarios that it has not specifically seen during training.
Multilingual Speech Synthesis
Models are now capable of generating speech in over seven thousand languages, many of which previously lacked sufficient data for traditional TTS development (Lux et al. 2024). Toucan is a toolkit for teaching, training, and using speech synthesis (IMS 2024).
TitaNet
A neural network architecture designed for speaker recognition tasks.
Variational Autoencoder (VAE)
A type of autoencoder that works probabilistically, combining a neural network architecture with a statistical model. VAEs are useful for generating new data that resembles the training data, such as synthesizing new audio samples mimicking specific voice attributes.
Unit Concatenation
The process of combining the outputs of multiple neural network layers (or “units”) by joining them end-to-end, allowing the network to preserve and use information from different sources simultaneously in subsequent layers.
Hidden Markov Model (HMM)
A statistical model used to predict unknown events based on known clues. It transitions between hidden states, with each state producing observable outputs based on probability rules.
Generative Adversarial Networks (GANs)
Machine learning models consisting of two neural networks, a “generator” and a “discriminator”, that compete against each other to create synthetic data.
Autoregressive Sequence-to-Sequence Models
Neural network architectures typically used for tasks like translation or text generation. They generate output sequences one element at a time, with each new element depending on previously generated elements.
Transformer Architecture
Uses self-attention mechanisms to process sequential data, allowing it to capture long-range dependencies without relying on recurrence or convolution.
Diffusion Denoising Probabilistic Models
Generative models that learn to gradually transform noise into structured data by iteratively denoising corrupted samples, reversing a diffusion process.
Infinite Impulse Response (IIR) Filters
Digital signal processing systems whose output depends on both current input and past outputs, potentially producing an infinite duration response to an impulse input.
Residual Style Adaptor
A neural network component designed to modify the style of generated content while preserving its core structure, typically used in style transfer tasks.
Uncertainty Modeling
The process of quantifying and representing the degree of uncertainty in data, predictions, or parameters, using probabilistic and statistical methods.